DeepRL: From On-Policy to Off-Policy
1 Why Off-Policy ?
1.1 Definition
On-policy存在的问题:第一种在策略梯度方法时候,需要每个训练周期分为两个阶段:
collect data
update model
1.2 策略梯度回顾
对于一个参数为 的执行者,策略梯度优化的目标是:
即最大化执行者在所有可能轨迹上的总回报的期望。
我们要计算目标函数对参数的梯度,暂时只考虑这一项和有关,那么只需要考虑这一项的梯度。不难求出这一项的梯度展开如下
通过梯度公式,将函数连乘的梯度转换为函数和的梯度。这里我们进一步合理假设环境变化的概率和执行者的参数无关,那么。于是我们计算出这一项梯度为:
所以目标函数的梯度可以写为:
注意最后参数要向着目标函数值增大的方向更新,所以时加上梯度乘以学习率。最后使用了优势函数来替换每一个episode的总体回报。常见的优势函数设计如下:
1.2 策略梯度的问题
策略梯度作为一种on-policy方法,阶段一中需要收集大量的轨迹数据,也就是多组学习者和环境交互的轨迹。这是一个非常耗时的过程,但在训练周期中收集的数据只能被用来更新一次参数,下一个周期就要重新收集(因为轨迹和学习参数相关!),这会导致训练的效率极低。
于是会自然的提出一个问题:我们是否可以从执行者参数无关的分布中采集数据?
重要性采样就是为了从一个新的分布中采样来替换旧的分布
2 Importance Sampling
对于一个分布,它的期望值可以这样计算:
不难发现,当从分布中采样,只要额外计算一个分式修正量(也称为重要性权重)即可。但是这里的分布并不是随便选择的,它需要至少符合下面的条件,才能保证期望的相等(无偏性)。
支撑集覆盖(support coverage):对于所有的地方,都有。否则某些区域将无法采样到,也就没法准确计算期望 ps: 积分区域的完整性
权重可计算且有限(Weight Computability and Finite Expectation)。
什么样的才算一个好的分布? 在无偏的背景下考虑方差,方差应该也要尽可能一致。
所以,只有当和尽可能一致的时候(分布相似,有点像废话)方差的差距才会比较小。
3 Off-policy
既然可以用一个新的分布采样原来的分布,那么我们就可以收集一次数据,更新多次模型参数。新的梯度如下:
此时的目标函数变为:
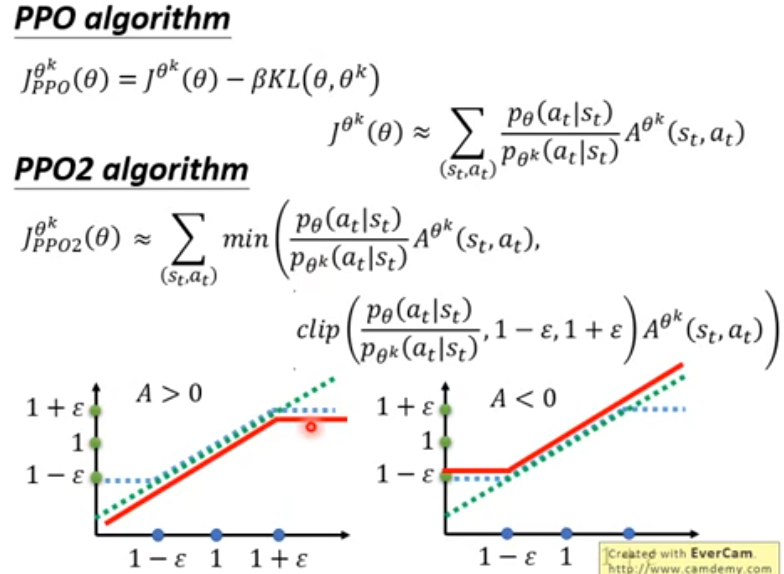
这时候我们需要约束学习的模型参数和采样的模型参数差距不能特别大,为此一个直觉的想法时,在目标函数上增加一项KL散度,使得两个参数下的策略空间的分布相似。这就是近端策略梯度优化:
自适应调整:
,增大
,减小
事实上这个KL也不是很好算,如何避免计算?